

Büyük Dil Modelleri nelerdir?
Büyük Dil Modelleri (LLM'ler), insan benzeri metinleri işlemek, anlamak ve oluşturmak için tasarlanmış gelişmiş yapay zeka (AI) sistemleridir. Derin öğrenme tekniklerine dayalıdırlar ve genellikle web siteleri, kitaplar ve makaleler gibi çeşitli kaynaklardan milyarlarca kelime içeren devasa veri kümeleri üzerinde eğitilirler. Bu kapsamlı eğitim, LLM'lerin dil, dilbilgisi, bağlam ve hatta genel bilginin bazı yönlerini kavramasını sağlar.
OpenAI'nin GPT-3'ü gibi bazı popüler LLM'ler, karmaşık dil görevlerini dikkate değer bir yeterlilikle halletmelerine olanak tanıyan, dönüştürücü adı verilen bir tür sinir ağı kullanır. Bu modeller, aşağıdakiler gibi çok çeşitli görevleri gerçekleştirebilir:
- Soruları cevaplama
- Metni özetleme
- Çeviri dilleri
- içerik oluşturma
- Kullanıcılarla etkileşimli konuşmalar yapmak bile
LLM'ler gelişmeye devam ettikçe, müşteri hizmetleri ve içerik oluşturmadan eğitim ve araştırmaya kadar çeşitli sektörlerdeki çeşitli uygulamaları geliştirmek ve otomatikleştirmek için büyük bir potansiyele sahiptir. Bununla birlikte, teknoloji ilerledikçe ele alınması gereken önyargılı davranış veya kötüye kullanım gibi etik ve toplumsal kaygıları da gündeme getiriyorlar.

Büyük Dil Modellerinin Popüler Örnekleri
Farklı sektör dikeylerinde yaygın olarak kullanılan LLM'lerin birkaç önemli örneğini burada bulabilirsiniz:
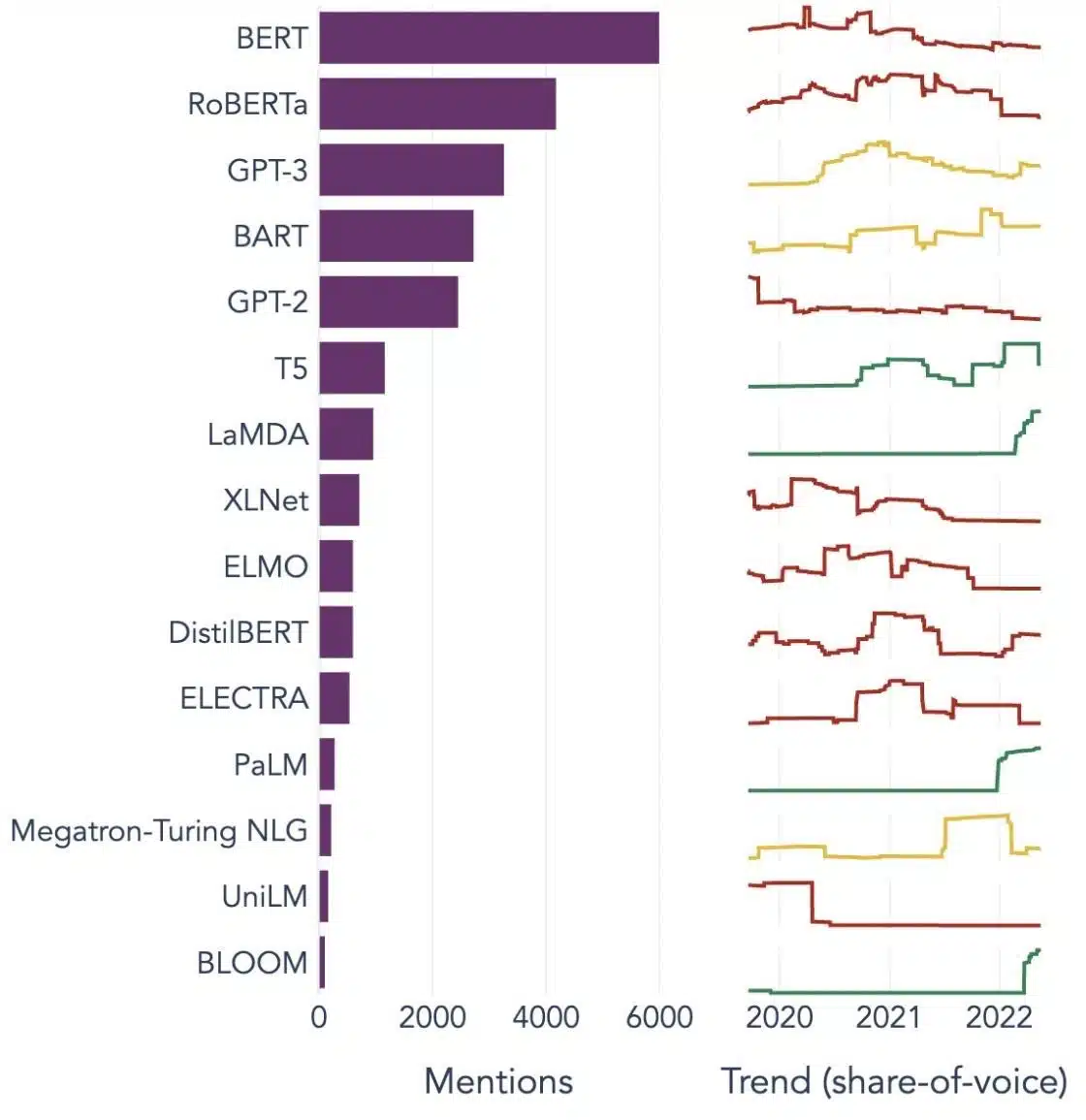
Resim Kaynak: Veri Bilimine Doğru
LLM modelleri nasıl eğitilir?
Büyük dil modellerini (LLM'ler) eğitmek, birkaç önemli adımı içeren oldukça büyük bir başarıdır. İşlemin basitleştirilmiş, adım adım özetini burada bulabilirsiniz:
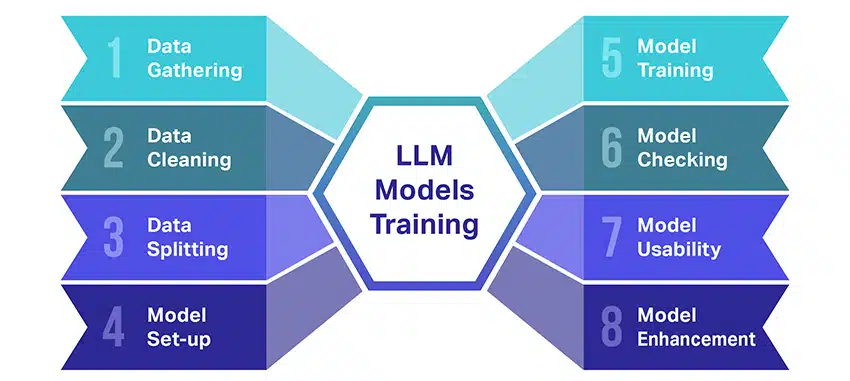
- Metin Verilerini Toplama: Bir LLM eğitimi, çok miktarda metin verisinin toplanmasıyla başlar. Bu veriler kitaplardan, web sitelerinden, makalelerden veya sosyal medya platformlarından gelebilir. Amaç, insan dilinin zengin çeşitliliğini yakalamaktır.
- Verileri Temizleme: Ham metin verileri daha sonra ön işleme adı verilen bir süreçte düzenlenir. Bu, istenmeyen karakterleri kaldırmak, metni belirteç adı verilen daha küçük parçalara bölmek ve hepsini modelin çalışabileceği bir formata dönüştürmek gibi görevleri içerir.
- Verileri Bölme: Ardından, temiz veriler iki kümeye bölünür. Modeli eğitmek için eğitim verileri olan bir küme kullanılacaktır. Diğer küme olan doğrulama verileri, daha sonra modelin performansını test etmek için kullanılacaktır.
- Modeli Kurma: LLM'nin mimari olarak bilinen yapısı daha sonra tanımlanır. Bu, sinir ağı türünün seçilmesini ve ağ içindeki katmanların ve gizli birimlerin sayısı gibi çeşitli parametrelere karar verilmesini içerir.
- Modeli Eğitmek: Asıl eğitim şimdi başlıyor. LLM modeli, eğitim verilerine bakarak, şimdiye kadar öğrendiklerine dayanarak tahminler yaparak ve ardından tahminleri ile gerçek veriler arasındaki farkı azaltmak için dahili parametrelerini ayarlayarak öğrenir.
- Modeli Kontrol Etme: LLM modelinin öğrenmesi, doğrulama verileri kullanılarak kontrol edilir. Bu, modelin ne kadar iyi performans gösterdiğini görmeye ve daha iyi performans için modelin ayarlarını değiştirmeye yardımcı olur.
- Modeli Kullanmak: Eğitim ve değerlendirme sonrasında LLM modeli kullanıma hazırdır. Artık, verilen yeni girdilere dayalı olarak metin üreteceği uygulamalara veya sistemlere entegre edilebilir.
- Modeli Geliştirmek: Son olarak, her zaman iyileştirme için yer vardır. LLM modeli, güncellenmiş veriler kullanılarak veya geri bildirime ve gerçek dünya kullanımına dayalı ayarlar düzenlenerek zaman içinde daha da geliştirilebilir.
Unutmayın, bu süreç, güçlü işlem birimleri ve büyük depolama gibi önemli hesaplama kaynaklarının yanı sıra makine öğreniminde uzmanlaşmış bilgi gerektirir. Bu nedenle genellikle gerekli altyapı ve uzmanlığa erişimi olan özel araştırma kuruluşları veya şirketler tarafından yapılır.
LLM, Denetimli veya Denetimsiz Öğrenmeye mi Dayanıyor?
Büyük dil modelleri genellikle denetimli öğrenme adı verilen bir yöntem kullanılarak eğitilir. Basit bir ifadeyle bu, onlara doğru cevapları gösteren örneklerden öğrendikleri anlamına gelir.
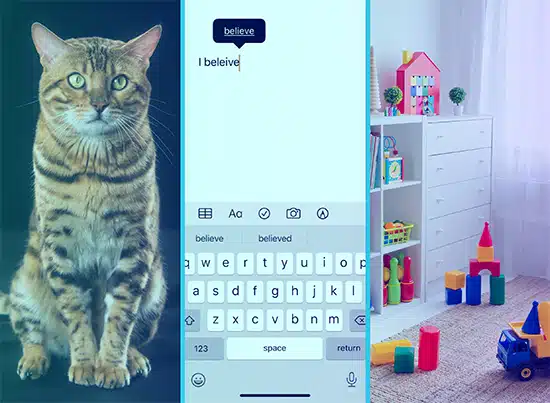 Bir çocuğa resimler göstererek kelimeleri öğrettiğinizi hayal edin. Onlara bir kedi resmi gösterip "kedi" dersiniz ve o resmi kelimeyle ilişkilendirmeyi öğrenirler. Denetimli öğrenme böyle çalışır. Modele çok sayıda metin ("resimler") ve karşılık gelen çıktılar ("kelimeler") verilir ve bunları eşleştirmeyi öğrenir.
Bir çocuğa resimler göstererek kelimeleri öğrettiğinizi hayal edin. Onlara bir kedi resmi gösterip "kedi" dersiniz ve o resmi kelimeyle ilişkilendirmeyi öğrenirler. Denetimli öğrenme böyle çalışır. Modele çok sayıda metin ("resimler") ve karşılık gelen çıktılar ("kelimeler") verilir ve bunları eşleştirmeyi öğrenir.
Dolayısıyla, bir LLM'ye bir cümle verirseniz, örneklerden öğrendiklerine dayanarak bir sonraki kelimeyi veya cümleyi tahmin etmeye çalışır. Bu şekilde, anlamlı ve bağlama uyan metinlerin nasıl üretileceğini öğrenir.
Bununla birlikte, bazen LLM'ler de biraz denetimsiz öğrenme kullanır. Bu, çocuğun farklı oyuncaklarla dolu bir odayı keşfetmesine ve kendi başına öğrenmesine izin vermek gibidir. Model, "doğru" cevaplar söylenmeden etiketlenmemiş verilere, öğrenme modellerine ve yapılara bakar.
Denetimli öğrenme, etiketli çıktı verilerini kullanmayan denetimsiz öğrenmenin aksine, girdiler ve çıktılarla etiketlenmiş verileri kullanır.
Özetle, LLM'ler esas olarak denetimli öğrenme kullanılarak eğitilirler, ancak keşif analizi ve boyut indirgeme gibi yeteneklerini geliştirmek için denetimsiz öğrenmeyi de kullanabilirler.
Büyük Bir Dil Modeli Eğitmek İçin Gerekli Veri Hacmi (GB Olarak) Ne Kadardır?
Konuşma verisi tanıma ve ses uygulamaları için olasılıklar dünyası çok büyüktür ve bunlar çeşitli endüstrilerde çok sayıda uygulama için kullanılmaktadır.
Büyük bir dil modelini eğitmek, özellikle gerekli veriler söz konusu olduğunda, herkese uyan tek bir süreç değildir. Bir dizi şeye bağlıdır:
- Model tasarımı.
- Hangi işi yapması gerekiyor?
- Kullanmakta olduğunuz veri türü.
- Ne kadar iyi performans göstermesini istiyorsunuz?
Bununla birlikte, LLM'leri eğitmek genellikle büyük miktarda metin verisi gerektirir. Ama ne kadar kütleden bahsediyoruz? Peki, gigabaytların (GB) çok ötesinde düşünün. Genellikle terabayt (TB) ve hatta petabayt (PB) veriye bakarız.
Çevredeki en büyük LLM'lerden biri olan GPT-3'ü düşünün. üzerinde eğitilir 570 GB metin verisi. Daha küçük LLM'ler daha azına ihtiyaç duyabilir – belki 10-20 GB veya hatta 1 GB gigabayt – ama yine de çok fazla.

Ancak bu sadece verilerin boyutuyla ilgili değil. Kalite de önemlidir. Modelin etkili bir şekilde öğrenmesine yardımcı olmak için verilerin temiz ve çeşitli olması gerekir. İhtiyacınız olan bilgi işlem gücü, eğitim için kullandığınız algoritmalar ve sahip olduğunuz donanım kurulumu gibi bulmacanın diğer önemli parçalarını da unutamazsınız. Tüm bu faktörler, bir LLM eğitiminde büyük rol oynar.
Büyük Dil Modellerinin Yükselişi: Neden Önemli?
LLM'ler artık sadece bir kavram veya deney değildir. Dijital ortamımızda giderek daha kritik bir rol oynuyorlar. Ama bu neden oluyor? Bu LLM'leri bu kadar önemli yapan nedir? Bazı temel faktörleri inceleyelim.
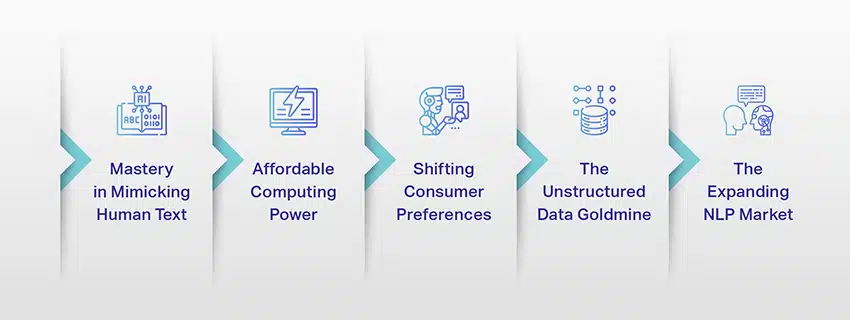
İnsan Metnini Taklit Etmede Ustalık
LLM'ler, dile dayalı görevleri ele alma şeklimizi değiştirdi. Sağlam makine öğrenimi algoritmaları kullanılarak oluşturulan bu modeller, bağlam, duygu ve hatta alaycılık dahil olmak üzere insan dilinin nüanslarını bir dereceye kadar anlama yeteneği ile donatılmıştır. İnsan dilini taklit etme yeteneği sadece bir yenilik değil, önemli sonuçları var.
LLM'lerin gelişmiş metin oluşturma yetenekleri, içerik oluşturmadan müşteri hizmetleri etkileşimlerine kadar her şeyi geliştirebilir.
Bir dijital asistana karmaşık bir soru sorabildiğinizi ve yalnızca anlamlı olmakla kalmayıp aynı zamanda tutarlı, ilgili ve sohbet havasında verilen bir yanıt aldığınızı hayal edin. LLM'lerin sağladığı şey budur. Daha sezgisel ve ilgi çekici bir insan-makine etkileşimini besliyor, kullanıcı deneyimlerini zenginleştiriyor ve bilgiye erişimi demokratikleştiriyor.
Uygun Fiyatlı Bilgi İşlem Gücü
Bilgisayar alanında paralel gelişmeler olmadan LLM'lerin yükselişi mümkün olmazdı. Daha spesifik olarak, hesaplama kaynaklarının demokratikleşmesi, LLM'lerin evriminde ve benimsenmesinde önemli bir rol oynamıştır.
Bulut tabanlı platformlar, yüksek performanslı bilgi işlem kaynaklarına benzeri görülmemiş erişim sunuyor. Bu şekilde, küçük ölçekli kuruluşlar ve bağımsız araştırmacılar bile gelişmiş makine öğrenimi modellerini eğitebilir.
Ayrıca, işlem birimlerindeki (GPU'lar ve TPU'lar gibi) gelişmeler, dağıtılmış bilgi işlemin yükselişiyle birleştiğinde, milyarlarca parametreli modellerin eğitilmesini mümkün kıldı. Bilgi işlem gücünün bu artan erişilebilirliği, LLM'lerin büyümesini ve başarısını mümkün kılarak, alanda daha fazla yenilik ve uygulamaya yol açıyor.
Değişen Tüketici Tercihleri
Bugünün tüketicileri sadece cevaplar istemiyor; ilgi çekici ve ilişkilendirilebilir etkileşimler istiyorlar. Daha fazla insan dijital teknolojiyi kullanarak büyüdükçe, daha doğal ve insani hissettiren teknolojiye olan ihtiyacın arttığı açıktır. LLM'ler bu beklentileri karşılamak için eşsiz bir fırsat sunuyor. Bu modeller, insan benzeri metinler üreterek, kullanıcı memnuniyetini ve sadakatini artırabilen ilgi çekici ve dinamik dijital deneyimler oluşturabilir. İster müşteri hizmetleri sağlayan yapay zeka sohbet botları, isterse haber güncellemeleri sağlayan sesli asistanlar olsun, LLM'ler bizi daha iyi anlayan bir yapay zeka çağını başlatıyor.
Yapılandırılmamış Veri Altın Madeni
E-postalar, sosyal medya gönderileri ve müşteri incelemeleri gibi yapılandırılmamış veriler, bir içgörü hazinesidir. üzerinde olduğu tahmin edilmektedir %80 kurumsal verilerin yüzdesi yapılandırılmamış ve hızla büyüyor %55 yıl başına. Bu veriler, uygun şekilde kullanılırsa işletmeler için bir altın madeni.
LLM'ler, bu tür verileri ölçekte işleme ve anlamlandırma yetenekleriyle burada devreye giriyor. Duyarlılık analizi, metin sınıflandırması, bilgi çıkarma ve daha fazlası gibi görevlerin üstesinden gelebilirler ve böylece değerli içgörüler sağlarlar.
İster sosyal medya gönderilerinden trendleri belirleme, ister incelemelerden müşteri duyarlılığını ölçme olsun, LLM'ler işletmelerin büyük miktarda yapılandırılmamış veride gezinmesine ve veriye dayalı kararlar almasına yardımcı oluyor.
Genişleyen NLP Pazarı
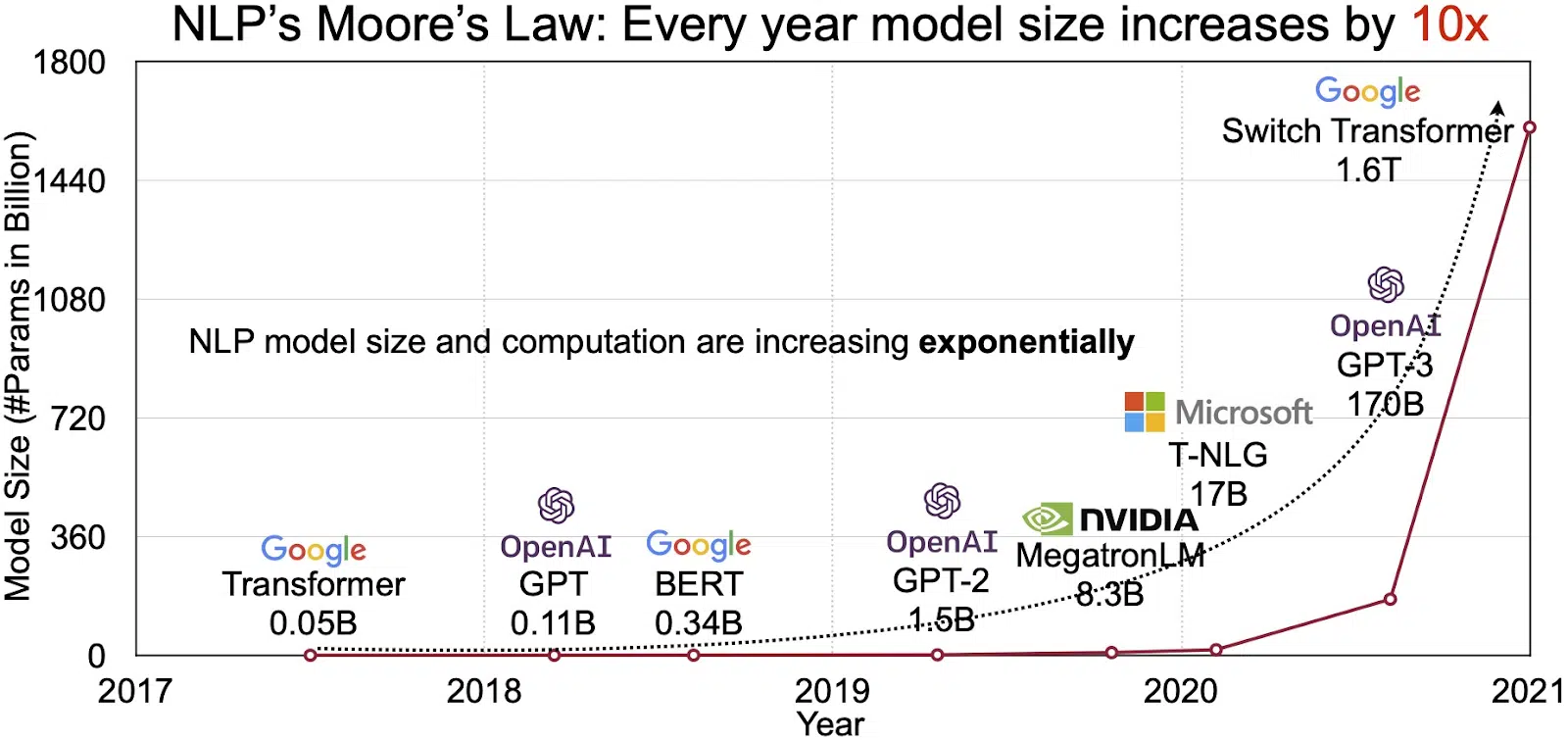
LLM'lerin potansiyeli, hızla büyüyen doğal dil işleme (NLP) pazarında yansıtılmaktadır. Analistler, NLP pazarının 11'de 2020 milyar dolardan 35'da 2026 milyar doların üzerine. Ancak genişleyen sadece pazarın büyüklüğü değil. Modellerin kendileri de hem fiziksel boyut hem de ele aldıkları parametre sayısı bakımından büyüyor. Aşağıdaki şekilde (resim kaynağı: bağlantı) görüldüğü gibi, LLM'lerin yıllar içindeki gelişimi, artan karmaşıklıklarının ve kapasitelerinin altını çizmektedir.
Büyük Dil Modellerinin Popüler Kullanım Durumları
LLM'nin en önemli ve en yaygın kullanım örneklerinden bazıları şunlardır:
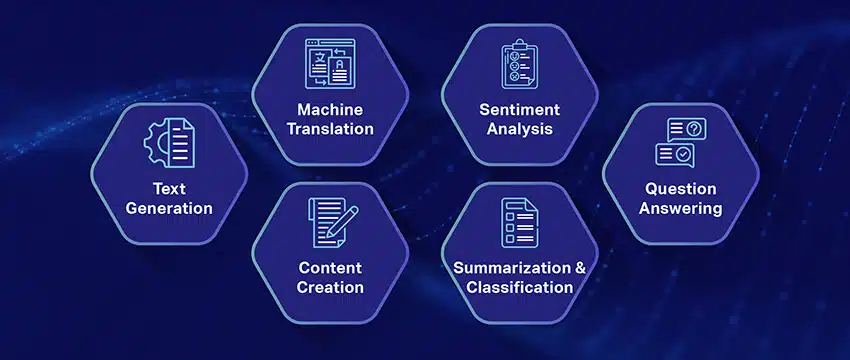
- Doğal Dilde Metin Oluşturma: Büyük Dil Modelleri (LLM'ler), doğal dilde metinleri özerk bir şekilde üretmek için yapay zekanın ve hesaplamalı dilbilimin gücünü birleştirir. Makale yazmak, şarkı hazırlamak veya kullanıcılarla sohbet etmek gibi çeşitli kullanıcı ihtiyaçlarını karşılayabilirler.
- Makineler aracılığıyla çeviri: LLM'ler, herhangi bir dil çifti arasında metin çevirmek için etkili bir şekilde kullanılabilir. Bu modeller, hem kaynak hem de hedef dillerin dilsel yapısını kavramak için tekrarlayan sinir ağları gibi derin öğrenme algoritmalarından yararlanır ve böylece kaynak metnin istenen dile çevrilmesini kolaylaştırır.
- Özgün İçerik Üretmek: LLM'ler, makinelerin tutarlı ve mantıksal içerik üretmesi için yollar açtı. Bu içerik, blog gönderileri, makaleler ve diğer içerik türleri oluşturmak için kullanılabilir. Modeller, içeriği yeni ve kullanıcı dostu bir şekilde biçimlendirmek ve yapılandırmak için derin öğrenme deneyimlerinden yararlanır.
- Duyguları Analiz Etmek: Büyük Dil Modellerinin ilginç bir uygulaması duygu analizidir. Burada model, açıklamalı metinde bulunan duygusal durumları ve hisleri tanımak ve kategorize etmek için eğitilmiştir. Yazılım, pozitiflik, negatiflik, tarafsızlık ve diğer karmaşık duygular gibi duyguları tanımlayabilir. Bu, çeşitli ürün ve hizmetler hakkında müşteri geri bildirimleri ve görüşleri hakkında değerli bilgiler sağlayabilir.
- Metni Anlamak, Özetlemek ve Sınıflandırmak: LLM'ler, AI yazılımının metni ve içeriğini yorumlaması için uygun bir yapı oluşturur. Modele çok büyük miktarda veriyi anlaması ve incelemesi talimatını veren LLM'ler, yapay zeka modellerinin metni farklı biçim ve kalıplarda anlamasına, özetlemesine ve hatta kategorilere ayırmasına olanak tanır.
- Soruları Cevaplamak: Büyük Dil Modelleri, Soru Yanıtlama (QA) sistemlerini bir kullanıcının doğal dil sorgusunu doğru bir şekilde algılama ve yanıtlama yeteneğiyle donatır. Bu kullanım örneğinin popüler örnekleri arasında, bir sorgunun bağlamını inceleyen ve kullanıcı sorularına ilgili yanıtlar vermek için geniş bir metin koleksiyonunu gözden geçiren ChatGPT ve BERT yer alır.

Konuşma Bölümü (POS) Etiketleme
Cümlelerdeki sözcükler, fiiller, isimler, sıfatlar vb. gibi dilbilgisel işlevleriyle etiketlenir. Bu süreç, modelin dilbilgisini ve sözcükler arasındaki bağlantıları anlamasına yardımcı olur.

Adlandırılmış Varlık Tanıma (NER)
Bir cümle içindeki kuruluşlar, konumlar ve kişiler gibi adlandırılmış varlıklar işaretlenir. Bu alıştırma, modele sözcüklerin ve tümcelerin anlamsal anlamlarını yorumlamada yardımcı olur ve daha kesin yanıtlar sağlar.

Duygu Analizi
Metin verilerine pozitif, nötr veya negatif gibi duyarlılık etiketleri atanır ve modelin cümlelerin duygusal alt tonunu kavramasına yardımcı olur. Duyguları ve görüşleri içeren soruları yanıtlarken özellikle yararlıdır.
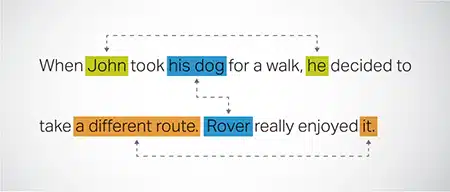
Koreferans Çözünürlüğü
Bir metnin farklı bölümlerinde aynı varlığa atıfta bulunulan örneklerin belirlenmesi ve çözümlenmesi. Bu adım, modelin cümlenin bağlamını anlamasına yardımcı olur ve böylece tutarlı yanıtlara yol açar.
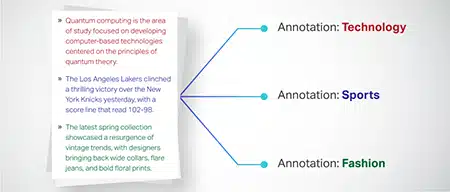
Metin Sınıflandırması
Metin verileri, ürün incelemeleri veya haber makaleleri gibi önceden tanımlanmış gruplara ayrılır. Bu, modelin metnin türünü veya konusunu ayırt etmesine yardımcı olarak daha uygun yanıtlar üretir.
Shaip'in Teklifi
Saip kuruluşların verilerini yönetmelerine, analiz etmelerine ve bunlardan en iyi şekilde yararlanmalarına yardımcı olacak çok çeşitli hizmetler sunar.
Veri Web Kazıma
Shaip tarafından sunulan önemli hizmetlerden biri veri kazımadır. Bu, alana özgü URL'lerden verilerin çıkarılmasını içerir. Shaip, otomatik araçlar ve teknikler kullanarak çeşitli web siteleri, Ürün Kılavuzları, Teknik Belgeler, Çevrimiçi forumlar, Çevrimiçi İncelemeler, Müşteri Hizmetleri Verileri, Sektör Düzenleyici Belgeler vb. çok sayıda kaynaktan ilgili ve spesifik verilerin toplanması.

Makine Çevirisi
Metni çeşitli diller arasında çevirmek için karşılık gelen transkripsiyonlarla eşleştirilmiş kapsamlı çok dilli veri kümelerini kullanarak modeller geliştirin. Bu süreç, dilsel engellerin ortadan kaldırılmasına yardımcı olur ve bilgiye erişilebilirliği destekler.
Taksonomi Çıkarma ve Oluşturma
Shaip, taksonomi çıkarma ve oluşturma konusunda yardımcı olabilir. Bu, verilerin farklı veri noktaları arasındaki ilişkileri yansıtan yapılandırılmış bir biçimde sınıflandırılmasını ve kategorize edilmesini içerir. Bu, işletmelerin verilerini organize etmede özellikle yararlı olabilir, verileri daha erişilebilir ve daha kolay analiz edilebilir hale getirir. Örneğin, bir e-ticaret işinde, ürün verileri ürün türü, marka, fiyat vb. temel alınarak kategorilere ayrılabilir ve bu da müşterilerin ürün kataloğunda gezinmesini kolaylaştırır.
Veri koleksiyonu
Veri toplama hizmetlerimiz, üretken yapay zeka algoritmalarını eğitmek ve modellerinizin doğruluğunu ve etkinliğini artırmak için gerekli olan kritik gerçek dünya veya sentetik verileri sağlar. Veriler, veri gizliliği ve güvenliği göz önünde bulundurularak tarafsız, etik ve sorumlu bir şekilde elde edilir.

Soru & Cevap
Soru yanıtlama (QA), doğal dil işlemenin, soruları insan dilinde otomatik olarak yanıtlamaya odaklanan bir alt alanıdır. QA sistemleri, olgusal, tanımsal ve görüşe dayalı olanlar da dahil olmak üzere çeşitli soru türlerini ele almalarını sağlayan kapsamlı metin ve kod üzerinde eğitilmiştir. Etki alanı bilgisi, müşteri desteği, sağlık hizmetleri veya tedarik zinciri gibi belirli alanlara uyarlanmış QA modelleri geliştirmek için çok önemlidir. Bununla birlikte, üretken KG yaklaşımları, modellerin yalnızca bağlama dayalı olarak alan bilgisi olmadan metin oluşturmasına olanak tanır.
Uzmanlardan oluşan ekibimiz, Soru-Cevap çiftleri oluşturmak için kapsamlı belgeleri veya kılavuzları titizlikle inceleyerek işletmeler için Üretken Yapay Zeka oluşturmayı kolaylaştırabilir. Bu yaklaşım, kapsamlı bir külliyattan ilgili bilgileri araştırarak kullanıcı sorgularını etkili bir şekilde ele alabilir. Sertifikalı uzmanlarımız, çeşitli konu ve alanlara yayılan en kaliteli Soru-Cevap çiftlerinin üretilmesini sağlar.

Metin Özetleme
Uzmanlarımız, kapsamlı metin verilerinden kısa ve öz ve anlayışlı özetler sunarak kapsamlı konuşmaları veya uzun diyalogları ayrıştırma yeteneğine sahiptir.

Metin Oluşturma
Haber makaleleri, kurgu ve şiir gibi farklı stillerde geniş bir metin veri kümesi kullanarak modelleri eğitin. Bu modeller daha sonra haber parçaları, blog girişleri veya sosyal medya gönderileri dahil olmak üzere çeşitli içerik türleri oluşturarak içerik oluşturma için uygun maliyetli ve zaman kazandıran bir çözüm sunar.
Konuşma Tanıma
Çeşitli uygulamalar için konuşma dilini kavrayabilen modeller geliştirin. Buna sesle etkinleştirilen asistanlar, dikte yazılımı ve gerçek zamanlı çeviri araçları dahildir. Süreç, karşılık gelen transkriptlerle eşleştirilmiş, konuşulan dilin ses kayıtlarından oluşan kapsamlı bir veri kümesinin kullanılmasını içerir.

Ürün önerileri
Müşterilerin satın alma eğiliminde olduğu ürünleri gösteren etiketler de dahil olmak üzere, müşteri satın alma geçmişlerine ilişkin kapsamlı veri kümelerini kullanarak modeller geliştirin. Amaç, müşterilere kesin öneriler sunarak satışları artırmak ve müşteri memnuniyetini artırmaktır.
Resim Altyazısı
Son teknoloji, yapay zeka destekli Resim Altyazısı hizmetimizle görüntü yorumlama sürecinizde devrim yaratın. Doğru ve bağlamsal olarak anlamlı açıklamalar üreterek resimlere canlılık aşılıyoruz. Bu, kitleniz için görsel içeriğinizle yenilikçi katılım ve etkileşim olanaklarının yolunu açar.

Metin Okuma Hizmetleri Eğitimi
Yapay zeka modellerini eğitmek için ideal olan, insan konuşma ses kayıtlarından oluşan kapsamlı bir veri kümesi sağlıyoruz. Bu modeller, uygulamalarınız için doğal ve ilgi çekici sesler üretebilir ve böylece kullanıcılarınız için ayırt edici ve sürükleyici bir ses deneyimi sunar.



